
Human-Written Or Machine-Generated: Finding Intelligence In Language Models [Hackaday]

What is the essential element which separates a text written by a human being from a text which has been generated by an algorithm, when said algorithm uses a massive database of human-written texts as its input? This would seem to be the fundamental struggle which society currently deals with, as the prospect of a future looms in which students can have essays auto-generated from large language models (LLMs) and authors can churn out books by the dozen without doing more than asking said algorithm to write it for them, using nothing more than a query containing the desired contents as the human inputs.
Due to the immense amount of human-generated text in such an LLM, in its output there’s a definite overlap between machine-generated text and the average prose by a human author. Statistical methods of detecting the former are also increasingly hamstrung by the human developers and other human workers behind these text-generating algorithms, creating just enough human-like randomness in the algorithm’s predictive vocabulary to convince the casual reader that it was written by a fellow human.
Perhaps the best way to detect machine-generated text may just be found in that one quality that these algorithms are often advertised with, yet which they in reality are completely devoid of: intelligence.
Statistically Human

For the longest time, machine-generated texts were readily identifiable by a casual observer in that they employed a rather peculiar writing style. Not only would their phrasing be exceedingly generic and ramble on with many repetitions, their used vocabulary would also be very predictable, using only a small subset of (popular) words rather than a more diverse and unpredictable vocabulary.
As time went on, however, the obviousness of machine-generated texts became less obvious, to the point where there’s basically a fifty-fifty chance of making the right guess, as recent studies indicate. For example Elizabeth Clark et al. with the GPT-2 and GPT-3 LLMs used in the study only convincing human readers in about half the cases that the text they were reading was written by a human instead of machine generated.
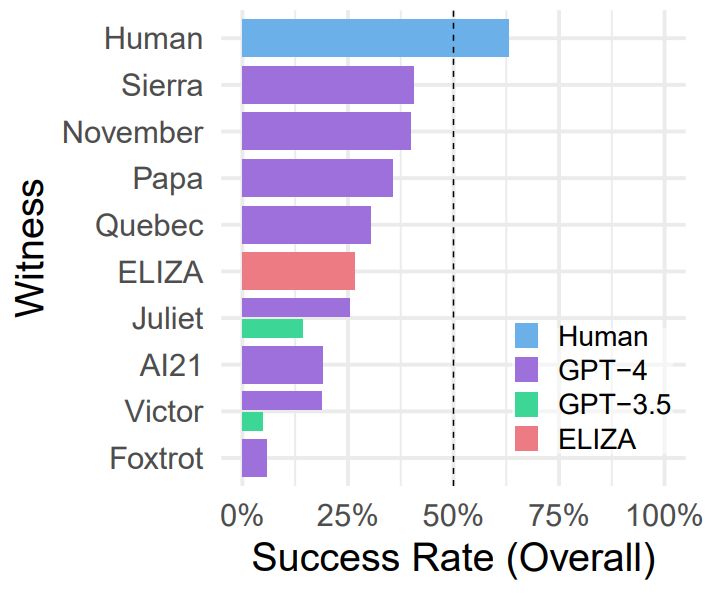 Overall Turing Test Success Rate (SR) for
Overall Turing Test Success Rate (SR) fora subset of witnesses. (Credit: Cameron Jones et al., 2023)
Then there are a string of Turing Test-related experiments, such as one by Daniel Jannai and colleagues, in which human participants only guessed the identity of their anonymous chat partner in 68% of the time. Another experiment by Cameron Jones and colleague focused primarily on the modern GPT-4 LLM, pitting it against other LLMs and early chatbots like 1960s’ famous ELIZA.
This last experiment is perhaps the most fascinating, as although it used a public online test, it pitted not just a single LLM against human interrogators, but rather a wide range of different technological approaches, each aimed at making a human believe that they’re talking with another intelligent human being. As can be observed from the test results (pictured), ELIZA was doing pretty well, handily outperforming the GPT-3.5 LLM and giving GPT-4 a run for its money. The crux of the issue – which is also addressed in the paper by Cameron Jones – would thus appear to be how a human reader judges the intelligence behind what they are reading, before they are confident that they’re talking with a real human being.
Since even real-life humans in this experiment got judged in many cases to not be ‘human’ enough, it raises the question of not only what distinguishes a human from an algorithm, but also in how far we are projecting our own biases and feelings onto the subject of a conversation or the purported author of a text.
Wanting To Believe
What is intelligence? Most succinctly, it is the ability to reason and reflect, as well as to learn and to possess awareness of not just the present, but also the past and future. Yet as simple as this sounds, we humans have trouble applying it in a rational fashion to everything from pets to babies born with anencephaly, where instinct and unconscious actions are mistaken for intelligence and reasoning. Much as our brains will happily see patterns and shapes where they do not exist, these same brains will accept something as human-created when it fits our preconceived notions.
People will often point to the output of ChatGPT – which is usually backed by the GPT-4 LLM – as an example of ‘artificial intelligence’, but what is not mentioned here is the enormous amount of human labor involved in keeping up this appearance. A 2023 investigation by New York Magazine and The Verge uncovered the sheer numbers of so-called annotators: people who are tasked with identifying, categorizing and otherwise annotating everything from customer responses to text fragments to endless amounts of images, depending on whether the LLM and its frontend is being used for customer support, a chatbot like ChatGPT or to find matching image data to merge together to fit the requested parameters.
This points to the most obvious conclusion about LLMs and similar: they need these human workers to function, as despite the lofty claims about ‘neural networks’ and ‘self-learning RNNs‘, language models do not posses cognitive skills, or as Konstantine Arkoudas puts it in his paper titled GPT-4 Can’t Reason: “[..] despite the occasional flashes of analytical brilliance, GPT-4 at present is utterly incapable of reasoning.”
In his paper, Arkoudas uses twenty-one diverse reasoning problems which are not part of any corpus that GPT-4 could have been trained on to pose both very basic and more advanced questions to a ChatGPT instance, with the results ranging from comically incorrect to mind-numbingly false, as ChatGPT fails to even ascertain that a person who died at 11 PM was logically still alive by noon earlier that day.
Finally, it is hard to forget cases where a legal professional tries to get ChatGPT to do his work for him, and gets logically disbarred for the unforgettably terrible results.
Asking Questions
Can we reliably detect LLM-generated texts? In a March 2023 paper by Vinu Sankar Sadasivan and colleagues, they find that no reliable method exists, as the simple method of paraphrasing suffices to defeat even watermarking. Ultimately, this would render any attempt to reliably classify a given text as being human- or machine-generated in an automated fashion futile, with the flipping of a coin likely to be about as accurate. Yet despite this, there is a way to reliably detect generated texts, but it requires human intelligence.
The author and lead developer of Curl – Daniel Stenberg – recently published an article succinctly titled The I in LLM stands for intelligence. In it he notes the influx of bug reports recently that have all or part of their text generated by an LLM, with the ‘bug’ in question being either completely hallucinated or misrepresented. This is a pattern that continues in the medical profession, with Zahir Kanjee, MD, and colleagues in a 2023 research letter to JAMA noting that GPT-4 managed to give the right diagnoses for provided cases in 64%, but only 39% of the time as its top diagnoses.
Although not necessarily terrible, this accuracy plummets when looking at pediatric cases, as Joseph Barile, BA and colleagues found in a 2024 research letter in JAMA Pediatrics. They noted that the ChatGPT chatbot with GPT-4 as its model had a diagnostic error rate of 83% (out of 100 cases). Of the rejected diagnoses, 72% were incorrect and 11% were clinically related but too vague to be considered a correct diagnosis. And then there is the inability of medical ‘AI’ to adapt to something as basic as new patients without extensive retraining.
All of this demonstrates both the lack of use of LLMs for professionals, as well as the very real risk when individuals who are less familiar with the field in question ask for ChatGPT’s ‘opinion’.
Signs Point To ‘No’
Although an LLM is arguably more precise than giving the good old Magic 8 Ball a shake, much like with the latter, an LLM’s response largely depends on what you put into it. Because of the relentless annotating, tweaking and adjusting of not just the model’s data, but also the front-ends and additional handlers for queries that an LLM simply cannot handle, LLMs give the impression of becoming better and – dare one say – more intelligent.
Unfortunately for those who wish to see artificial intelligence of any form become a reality within their lifetime, LLMs are not it. As the product of immense human labor, they are a far cry from the more basic language models that still exist today on for example our smartphones, where they learn only our own vocabulary and try to predict what words to next add to the auto-complete, as well as that always praised auto-correct feature. Moving from n-gram language models to RNNs enabled larger models with increased predictive ability, but just scaling things up does not equate intelligence.
To a cynical person, the whole ‘AI bubble’ is likely to feel like yet another fad as investors try to pump out as many products with the new hot thing in or on it, much like the internet bubble, the NFT/crypto bubble and so many before. There are also massive issues with the data being used for these LLMs, as human authors have their work protected by copyright.
As the lawsuits by these authors wind their way through the courts and more studies and trials find that there is indeed no intelligence behind LLMs other than the human kind, we won’t see RNNs and LLMs vanish, but they will find niches where their strengths do work, as even human intellects need an unthinking robot buddy sometimes who never loses focus, and never has a bad day. Just don’t expect them to do our work for us any time soon.