
![air-canada’s-chatbot:-why-rag-is-better-than-an-llm-for-facts-[hackaday]](https://i0.wp.com/upmytech.com/wp-content/uploads/2024/02/170665-air-canadas-chatbot-why-rag-is-better-than-an-llm-for-facts-hackaday-scaled.jpg?resize=800%2C445&ssl=1)
Air Canada’s Chatbot: Why RAG is Better Than an LLM For Facts [Hackaday]

Recently Air Canada was in the news regarding the outcome of Moffatt v. Air Canada, in which Air Canada was forced to pay restitution to Mr. Moffatt after the latter had been disadvantaged by advice given by a chatbot on the Air Canada website regarding the latter’s bereavement fare policy. When Mr. Moffatt inquired whether he could apply for the bereavement fare after returning from the flight, the chatbot said that this was the case, even though the link which it provided to the official bereavement policy page said otherwise.
This latter aspect of the case is by far the most interesting aspect of this case, as it raises many questions about the technical details of this chatbot which Air Canada had deployed on its website. Since the basic idea behind such a chatbot is that it uses a curated source of (company) documentation and policies, the assumption made by many is that this particular chatbot instead used an LLM with more generic information in it, possibly sourced from many other public-facing policy pages.
Whatever the case may be, chatbots are increasingly used by companies, but instead of pure LLMs they use what is called RAG: retrieval augmented generation. This bypasses the language model and instead fetches factual information from a vetted source of documentation.
Why LLMs Don’t Do Facts
A core problem with using LLMs and expecting these to answer questions truthfully is that this is not possible, due to how language models work. What these act on is the likelihood of certain words and phrases occurring in sequence, but there is no ‘truth’ or ‘falsehood’ embedded in their parameter weights. This often leads to jarring situations with chatbots such as ChatGPT where it can appear that the system is lying, changing its mind and generally playing it fast and loose with factual statements.
The way that this is generally dealt with by LLM companies such as OpenAI is by acting on a negative response by the human user to the query by essentially running the same query through the LLM again, with a few alterations to hopefully get a response that the inquisitive user will find more pleasing. It could hereby be argued that in order to know what ‘true’ and ‘false’ is some level of intelligence is required, which is something that LLMs by design are completely incapable of.
With the Air Canada case this is more than obvious, as the chatbot confidently stated towards Mr. Moffatt among other things the following:
Air Canada offers reduced bereavement fares if you need to travel because of an imminent death or a death in your immediate family.
…
If you need to travel immediately or have already travelled and would like to submit your ticket for a reduced bereavement rate, kindly do so within 90 days of the date your ticket was issued by completing our Ticket Refund Application form.
Here the underlined ‘bereavement fares’ section linked to the official Air Canada policy, yet the chatbot had not cited this answer from the official policy document link. An explanation could be that the backing model was trained with the wrong text, or that a wrong internal policy document was queried, but the ’90 days’ element is as far as anyone can determine – including the comment section over at the Ars Technica article on the topic – not something that has ever been a policy at this particular airline. What’s also interesting is that Air Canada has now removed the chatbot from its site, all of which suggests that it wasn’t using RAG.
Grounding LLMs With RAGs
LLMs have a lot of disadvantages when it comes to factual information, even beyond the aforementioned. Where an LLM is also rather restrictive is when it comes to keeping up to date with new information, as inside the model new information will have to be integrated as properly weighed (‘trained’) parameters, while the old data should be removed or updated. Possibly a whole new model has to be trained from fresh training data, all of which makes running an LLM-based chatbot computationally and financially expensive to run.
In a run-down by IBM Research they go over many of these advantages and disadvantages and why RAGs make sense for any situation where you not only want to be able to trust a provided answer, but also want to be able to check the sources. This ‘grounding’ of an LLM means effectively bypassing it and running the system more like a traditional Internet search engine, although the LLM is still used to add flavor text and the illusion of a coherent conversation as it provides more flexibility than a chatbot using purely static scripts.
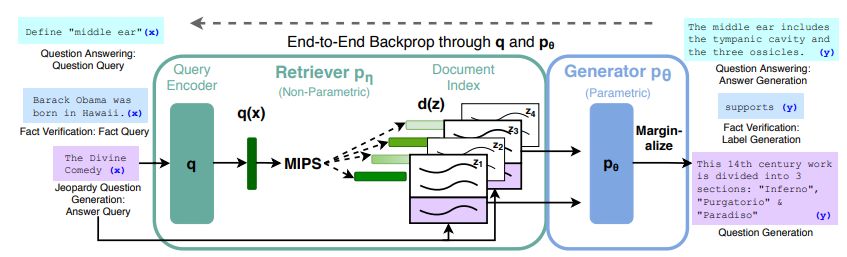
The idea of using these more traditional methods with LLMs to keep them from going off the rails was first pitched by Meta (née Facebook) in a 2020 paper, in which they used a neural network-based retriever to access information in a vector index of Wikipedia. This supports a range of different types of queries, including questions, fact verification and generating trivia questions. The retriever component thus only has to be trained to be able to find specific information in the prepared documents, which immediately adds the ability to verify the provided information using these documents rather than rely on a highly opaque parameterized model.
In the IBM provided example, they paint a scenario where an employee asks a number of questions to a company chatbot, which pulls up the employee’s HR files, checks available vacation days, matches the request against company policies and combines the resulting information into a response. Of course, in the Facebook paper it is noted that RAG-enhanced LLMs are still very much capable of ‘hallucinating’ and need ‘fine-tuning’ to keep them in line. On the bright side, a result of using RAG is that sources can be provided and linked, so that said employee can then check those to verify that the response was correct.
LLMs Are Still Dumb
The problematic part with chatbots is that unless they have been carefully scripted by a human being (with QA validating their work), they are bound to mess up. With pure LLM-based chatbots this is beyond question, as the responses provided range between plausible to completely delusional. Grounding LLMs with RAG reduces the amount of made-up nonsense, but in the absence of any intelligence and comprehension of what the algorithm generates as a response, there also cannot be any accountability.
That is, the accountability (and liability) shifts to the entity which opted to put the chatbot in place, as was succinctly and rightfully demonstrated in Moffatt v. Air Canada. In the end no matter how advanced or complex the system and its algorithms are, the liability remains with the human element in charge. As the Civil Resolution Tribunal’s judge who presided over the case states in the ruling: “It should be obvious to Air Canada that it is responsible for all the information on its website. It makes no difference whether the information comes from a static page or a chatbot.”
In light of such a case, a company should strongly question whether there is any conceivable benefit to having a chatbot feature on their public-facing website rather than a highly capable search functionality which could still use natural language processing to provide more relevant search results, but which leaves the linked results to human-written and human-validated documents as the authoritative response. For both Air Canada and Mr. Moffatt such a system would have been a win-win and this whole unpleasant business could have been avoided.